大型網(wǎng)站技術(shù)架構(gòu) 數(shù)據(jù)處理與存儲(chǔ)支持服務(wù)深度解析
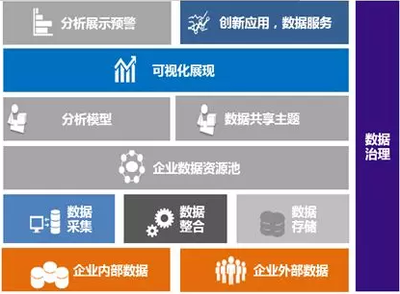
在大型網(wǎng)站技術(shù)架構(gòu)中,數(shù)據(jù)處理和存儲(chǔ)支持服務(wù)是確保系統(tǒng)高效、穩(wěn)定運(yùn)行的核心。本摘要與讀書筆記圍繞數(shù)據(jù)存儲(chǔ)、數(shù)據(jù)處理以及相關(guān)服務(wù)的設(shè)計(jì)與實(shí)現(xiàn)展開,結(jié)合實(shí)際案例與理論,探討了如何構(gòu)建可擴(kuò)展、高可用的數(shù)據(jù)處理與存儲(chǔ)體系。
一、數(shù)據(jù)處理的關(guān)鍵技術(shù)與策略
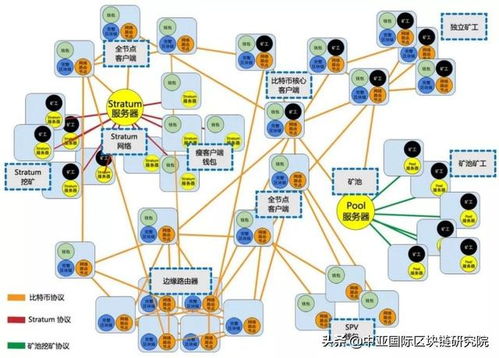
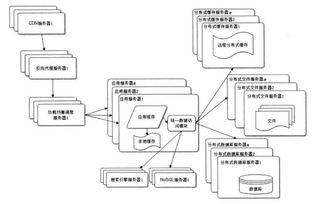
數(shù)據(jù)處理主要包括數(shù)據(jù)采集、轉(zhuǎn)換、存儲(chǔ)和查詢分析等環(huán)節(jié)。在大型網(wǎng)站中,數(shù)據(jù)量巨大且來源多樣,因此需要采用分布式處理技術(shù)。常見的框架如Hadoop和Spark,能夠并行處理海量數(shù)據(jù),提高處理速度。例如,通過MapReduce模型,Hadoop將任務(wù)分解為多個(gè)小任務(wù)在集群中并行執(zhí)行,大大縮短了數(shù)據(jù)處理時(shí)間。流處理技術(shù)(如Apache Kafka和Flink)支持實(shí)時(shí)數(shù)據(jù)處理,適用于需要快速響應(yīng)的場景,如推薦系統(tǒng)或欺詐檢測。讀書筆記強(qiáng)調(diào),設(shè)計(jì)數(shù)據(jù)處理流程時(shí),應(yīng)考慮數(shù)據(jù)一致性和容錯(cuò)性,例如通過復(fù)制和分片機(jī)制來避免單點(diǎn)故障。
二、存儲(chǔ)支持服務(wù)的架構(gòu)與優(yōu)化
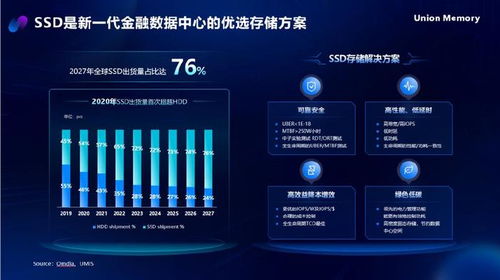
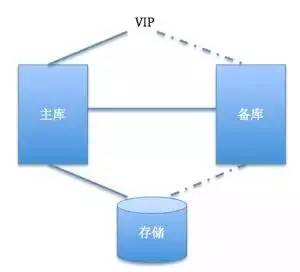
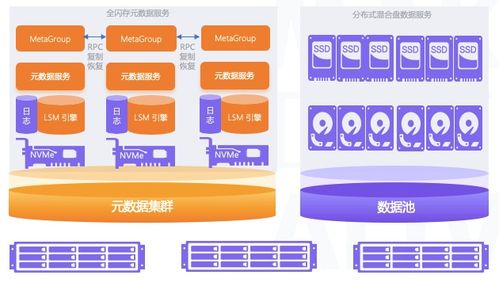
存儲(chǔ)是數(shù)據(jù)處理的基礎(chǔ),大型網(wǎng)站通常采用分層存儲(chǔ)策略,結(jié)合關(guān)系型數(shù)據(jù)庫(如MySQL)和非關(guān)系型數(shù)據(jù)庫(如NoSQL)。關(guān)系型數(shù)據(jù)庫適用于事務(wù)性操作,保證ACID特性,但在高并發(fā)場景下可能成為瓶頸。因此,NoSQL數(shù)據(jù)庫(如MongoDB、Cassandra)被廣泛用于處理非結(jié)構(gòu)化數(shù)據(jù),支持水平擴(kuò)展。例如,Cassandra采用分布式架構(gòu),通過一致性哈希算法實(shí)現(xiàn)數(shù)據(jù)分片,確保高可用性。緩存技術(shù)(如Redis)作為存儲(chǔ)的補(bǔ)充,能夠顯著提升讀取性能,減少數(shù)據(jù)庫負(fù)載。讀書筆記指出,在選擇存儲(chǔ)方案時(shí),應(yīng)根據(jù)數(shù)據(jù)訪問模式進(jìn)行優(yōu)化,例如使用索引和分區(qū)策略來提高查詢效率。
三、實(shí)際應(yīng)用與挑戰(zhàn)
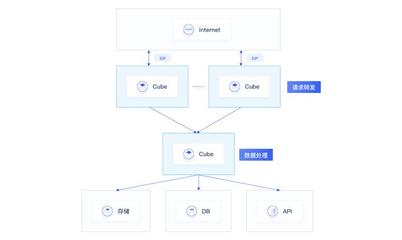
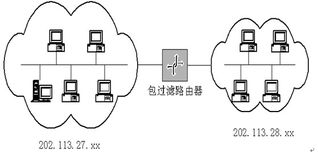
在實(shí)際應(yīng)用中,數(shù)據(jù)處理和存儲(chǔ)服務(wù)需要與整體架構(gòu)緊密結(jié)合。以電商網(wǎng)站為例,用戶行為數(shù)據(jù)通過Kafka實(shí)時(shí)采集,存儲(chǔ)于Hadoop集群進(jìn)行批處理分析,同時(shí)使用Elasticsearch提供快速搜索服務(wù)。挑戰(zhàn)依然存在,如數(shù)據(jù)安全和隱私保護(hù)、系統(tǒng)擴(kuò)展時(shí)的數(shù)據(jù)遷移問題。讀書筆記建議,采用加密和訪問控制機(jī)制保護(hù)數(shù)據(jù),同時(shí)通過自動(dòng)化工具(如Kubernetes)管理存儲(chǔ)資源,實(shí)現(xiàn)彈性伸縮。
數(shù)據(jù)處理和存儲(chǔ)支持服務(wù)是大型網(wǎng)站架構(gòu)的基石。通過合理設(shè)計(jì)分布式處理和分層存儲(chǔ),可以構(gòu)建出高效、可靠的數(shù)據(jù)系統(tǒng)。讀者應(yīng)注重理論與實(shí)踐結(jié)合,不斷優(yōu)化架構(gòu),以應(yīng)對(duì)日益增長的數(shù)據(jù)需求。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.vcfw.cn/product/23.html
更新時(shí)間:2026-01-23 17:50:23